


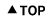

2차 결제하기(클릭)
위의 2차 결제하기 버튼을
클릭해주세요.
2차 결제 미진행시 배송료가
추가 결제될 수 있습니다.
수험정보홈>국제자격증>FDP>수험정보
About FDP
FDP(Financial Data Professional, 금융데이터분석전문가)는 Big Data, Machine Learning, AI(artificial intelligence) 등의 기술 발달이 주도하는 디지털 전환(Digital Transformation)에 대비하여 관련 기술의 이론과 원리를 이해하고 금융 분야와 관련한 다양한 데이터를 알고리즘에 자유자재로 적용하고 분석할 수 전문가입니다.
최근 금융 산업은 디지털 전환으로 급변하고 있습니다. 이에 기존 금융 산업 내 종사자뿐만 아니라 금융 산업으로의 취업을 꿈꾸는 취업준비생과 학생에게도 Big Data, Machine Learning, AI 등 디지털 전환과 관련한 이론 및 실무 지식이 요구되고 있습니다. 이러한 변화에 발 빠르게 대처하지 않으면 빠르게 진화하고 있는 금융 산업에서 살아남기 어렵습니다.
순수 Big Data, Machine Learning, AI 등의 이론과 개념은 광범위할 뿐 아니라 통계, 선형대수, 프로그래밍 등의 사전 배경 지식을 기본적으로 요구합니다. 이상적으로 사전 배경 지식을 습득하고, 관련 이론과 개념을 배우고 이해하면 좋겠지만, 현실적으로 상당 시일의 시간과 학습 노력이 필요함에 따라 달성하기 쉽지 않습니다. FDP 시험은 선택과 집중을 통해 이에 대한 해결책을 제시합니다. 금융과 밀접한 Big Data, Machine Learning, AI 등을 선별하여 관련 이론과 개념을 배움으로써 초기 진입 장벽을 낮춰주고 금융인으로서 당장 필요할 수 있는 기술 적용 사례 등에 집중함으로써 필요에 의해 공부할 환경을 조성해줍니다.
FDP 협회는 Big Data, Machine Learning, AI 등의 배경 지식 범위를 금융 분야와 관련한 내용 중심으로 구성하여 “금융 데이터 사이언스”에 대한 중요한 개념과 이론 및 실무 지식을 배울 수 있도록 교과 과목을 완성하였습니다. 기초 확률 및 통계, Big Data, Machine Learning, AI 등에 대한 이론 지식부터 실무 적용 사례, 관련 최신 학술 논문에 이르기까지 금융데이터분석전문가가 되기 위한 초석으로의 학습 자료로서의 완성도가 높습니다.
2019년부터 시행되고 있는 FDP 시험 역시 디지털 전환에 따른 금융 산업 변화와 함께 진화하고 있습니다. 금융권 내 대체 데이터(alternative data)에 대한 수요와 공급 증가, 기계학습 알고리즘 및 인공지능 기법을 활용한 금융서비스 증가 등 최신 금융 산업 내 기술 적용 추세와 새로운 기술과 금융 및 경제 이론의 조화 등의 내용은 현 금융 산업 내 종사자 및 예비 종사자에게 디지털 전환에 적절히 대비할 수 있는 양질의 지식을 얻을 수 있는 좋은 기회를 제공합니다.
1.시험 접수 절차
| STEP 1 | FDP 협회 홈페이지(www.fdpinstitute.org)에서 회원가입을 합니다. |
|---|---|
| STEP 2 | FDP 협회가 제공하는 안내서(handbook)를 주의 깊게 읽어봅니다. |
| STEP 3 | FDP 협회 시험 등록 기간 및 등록비용을 확인하고, 비용 결제까지 완료합니다. |
| STEP 4 |
시험 응시 장소 결정 : 코로나 19의 영향으로 시험 응시 장소는 2가지 선택지가 있습니다. Option 1 : Prometric Testing Center* 에 직접 가서 시험 응시 Option 2 : Remotely Proctored Testing으로 수험생이 직접 장소를 선택하고, FDP에서 요구하는 카메라 환경 등을 구비하여 시험 응시 * Prometric Testing Center 주소 : 서울 중구 퇴계로 성우 빌딩 6층 HSF Inc. |
2.응시 자격
· 별도의 자격요건은 없으나 FDP 시험을 치루기 이전 혹은 이후에 Python, R 등에 대한 기초 온라인 수업을 수강하여야 합니다.
· 온라인 수업은 Datacamp, Udemy 중 하나를 선택하여 수강하면 되고, 대략 10-21시간 정도의 분량입니다.
· 온라인 수강 완료 후 수료 완료에 대한 수료증을 제출해야 합니다.
(https://www.cognitoforms.com/CAIAAssociation1/submityouronlinecertificatesofcompletion)
| 웹사이트 | 프로그램 | 수강 과목 |
|---|---|---|
|
Datacamp (https://www.datacamp.com) |
Python | Introduction to Python (https://www.datacamp.com/courses/intro-to-python-for-data-science) |
| Intermediate Python for Data Science (https://www.datacamp.com/courses/intermediate-python-for-data-science) |
||
| R | Introduction to R (https://www.datacamp.com/courses/free-introduction-to-r) |
|
| Intermediate R (https://www.datacamp.com/courses/intermediate-r) |
||
|
Udemy (https://www.udemy.com/) |
Python (choose one) |
Python Programming for Beginners: Learn Python In 9 Days (https://www.udemy.com/course/python-programming-for-beginners-learn-python-in-9-days/) |
| The Python BibleTM | Everything You Need to Program in Python (https://www.udemy.com/course/the-python-bible/) |
||
| R | R Programming - R Language for Absolute Beginners (https://www.udemy.com/course/r-for-absolute-beginners/) |
1. 시험 비용
Exam Fees
| Registration | Late Registration | Retake | |
| Registration Fee(refund policy) | $1,100 | $1,300 | $500 |
| Enrollment Fee(refund policy) | $400 | $400 | - |
| Total FDP Exam Fee | $1,500** | $1,700** | $500** |
* Exam fees do
** Canadian taxes will be applied
2.시험 구성
| 시험 시간 | 4시간 |
|---|---|
| 문제 구성 | 객관식(3지 혹은 4지 선다형) 문항 80개(75%비중) & 주관식 3~4개 세트(25%비중) |
| 문제 유형 | Multiple Choice Questions(객관식) & Constructed Response Questions(주관식) |
| 채점방식 | FDP 협회에서 합격점수에 대한 정보 비공개 |
· 시험은 CBT(Computer-based testing으로 진행되며 응시 후 결과는 통상 5주일 이내에 공개됩니다.
· 점수는 공개되지 않고, 각 토픽별로 응시생 평균을 상회했는지 하회했는지 정도만 공개됩니다.
· 결과 재검토 요청이 가능하며, 재검토 요청 비용은 $100입니다.
| Exam day schedule | |
|---|---|
| Nondisclosure Agreement (must be completed within 5 minutes) | 5 minutes |
| Exam instructions | 10 minutes |
| FDP Multiple Choice Questions | 135 minutes |
| Nondisclosure Agreement (must be completed within 5 minutes) | 5 minutes |
| Break (optional) | 20 minutes |
| FDP Constructed Response Questions | 65 minutes |
| Comment Period (Optional) | 10 minutes |
| Exam Session Time | 4 Hours |
· 시험은 총 4시간으로 2개의 Section으로 구성되며, 휴식시간은 20분입니다.
· 객관식 시험(Multiple Choice Questions)은 3지선다형과 4지선다형 문제가 함께 출제됩니다.
· 객관식 시험은 135분 동안 80문제를 풀어야 합니다.
· 주관식 시험(Constructed Response Questions)은 주관식으로 3~4문제가 출제됩니다.
· 주관식 시험은 65분 동안 Essay 3~4세트를 풀어야 합니다.
· 객관식, 주관식 시험 모두 오답에 대한 패널티는 없습니다.
■ Multiple Choice sample screen shot
■ Constructed Response sample screen shot

3.FDP 시험과목 및 출제비중
| Topics | Approximate Weight % |
|---|---|
| 1. Introduction to Data Science | 5-10 |
|
■ Data analytic thinking ■ Business problems and data science solutions ■ Adoption of alternative data ■ The risks and rewards of alternative data for investment decisions ■ Advanced technologies for alpha ■ Alternative data vendor profiles ■ The future of alternative data ■ Warming up to collective intelligence investing (CII) ■ Getting started with alternative data and CII ■ Balancing the risks and rewards of CII from different platform types ■ The road ahead for investment managers ■ Understanding why “Wall Street” wants data ■ Building a data product ■ Delivering your data ■ Marketing and selling your data ■ Protecting yourself and your data ■ Pricing your data ■ Case studies Readings for Introduction to Data Science & Big Data 1. Provost, F. and T. Fawcett. (2013). Data Science for Business. Sebastopol, CA: O’Reilly Media Inc. • Chapter 1 – Introduction : Data-Analytic Thinking • Chapter 2 – Business Problems and Data Solutions 2. Dannemiller, D. and R. Kataria. (2017). Alternative data for investment decisions: Today’s innovation could be tomorrow’s requirement by Deloitte Center for Financial Services. 3. Gajjaria, A. (2018). Collective intelligence investing: Alpha generation via alternative data brings new risks by Deloitte Center for Financial Services. 4. Quandl (2017). Sell Your Data to Wall Street: The comprehensive guide to monetizing your data assets for professional investors. |
|
| 2. Linear & Logistic Regression, Support Vector Machines, Regularization, and Time Series | 10 - 15 |
|
■ Organization and resources of the book An Introduction to Statistical Learning: with applications in R ■ Statistical learning ■ Assessing Model Accuracy ■ Motivation for using neural nets to recognize handwritten digits ■ Perceptron neurons ■ Sigmoid neurons ■ The architecture of neural networks ■ A simple network to classify handwritten digits ■ Learning with gradient descent ■ Implementing a network to classify digits ■ Why deep learning matters Readings for Machine Learning: Introduction to Algorithms 1. James, G., D. Witten, T. Hastie and R. Tibshirani. (2013). An Introduction to Statistical Learning: with applications in R. New York, NY: Springer. Chapters 1, 2.1 & 2.2 • Chapter 1 – Introduction • Chapter 2.1 - What is Statistical Learning? • Chapter 2.2 – Assessing Model Accuracy 2. Nielsen, M. A. (2015). Using Neural Networks to Recognize Handwritten Digits. In Neural Networks and Deep Learning, Determination Press |
|
| 3. Decision Trees, Supervised Segmentation, and Ensemble Methods | 8 - 12 |
|
■ Models, induction and prediction ■ Supervised segmentation ■ Visualizing segmentations ■ Classification via mathematical functions ■ Regression via mathematical functions ■ Simple linear regression ■ Multiple linear regression ■ Considerations in the regression model ■ Concepts of time series ■ Statistical models ■ Modeling volatility Readings for Machine Learning: Regression, Support Vector Machine, Time Series Models 1. Provost, F. and T. Fawcett. (2013). Data Science for Business. Sebastopol, CA: O’Reilly Media Inc. • Chapter 3 - Introduction to Predictive Modeling: From Correlation to Supervised Segmentation • Chapter 4 - Fitting a Model to Data 2. James, G., D. Witten, T. Hastie and R. Tibshirani. (2013). An Introduction to Statistical Learning: with applications in R. New York, NY: Springer • Chapter 3 – Simple Linear Regression 3. Aas, K. and X. K. Dimakos. (2004). Statistical modeling of financial time series: An introduction. Oslo Norway: Norwegian Computing Center |
|
| 4. Classification, Clustering, and Naïve Bayes | 8 - 12 |
|
■ Overfitting and its avoidance ■ Subset selection ■ Shrinkage methods ■ Tree-Based methods Readings for Machine Learning: Regularization, Regression Trees, Random Forest & Overfitting 1. Provost, F. and T. Fawcett. (2013). Data Science for Business. Sebastopol, CA: O’Reilly Media Inc. • Chapter 5 – Overfitting and Its Avoidance 2. James, G., D. Witten, T. Hastie and R. Tibshirani. (2013). An Introduction to Statistical Learning: with applications in R. New York, NY: Springer. • Chapter 6.1 – Best Subset Selection • Chapter 6.2 – Shrinkage Methods • Chapter 8.1 – The Basics of Decision Trees • Chapter 8.2 – Bagging, Random Forests, Boosting 3. Aas, K. and X. K. Dimakos. (2004). Statistical modeling of financial time series: An introduction. Oslo Norway: Norwegian Computing Center |
|
| 5. Neural Networks and Reinforcement Learning | 8 - 12 |
|
■ Calculating and interpreting similarity and distance ■ Discussing technical details related to similarities and neighbors ■ Describing and evaluating classifiers ■ Describing a key analytical framework and calculating expected values Readings for Machine Learning: Classification & Clustering 1. Provost, F. and T. Fawcett. (2013). Data Science for Business. Sebastopol, CA: O’Reilly Media Inc. • Chapter 6 – Similarity, Neighbors, and Clusters • Chapter 7 – Decision Analytic Thinking : What Is a Good Model? |
|
| 6. Performance Evaluation, Back-Testing, and False Discoveries | 5 - 10 |
|
■ Visualizing model performance ■ Backtesting protocol in the era of machine learning ■ An investigation of the false discovery rate and the misinterpretation of p-values ■ A data science solution to the multiple-testing crisis Readings for Machine Learning : Performance Evaluation, Support Vector Machines & False Discoveries 1. Provost, F. and T. Fawcett. (2013). Data Science for Business. Sebastopol, CA: O’Reilly Media Inc. • Chapter 8 – Similarity, Neighbors, and Clusters 2. Arnott, R., C. B. Harvey, and H. Markowitz. (2019). A Backtesting Protocol in the Era of Machine Learning. Journal of Financial Data Science, 1(1), 64-74 3. Colquhoun, D. (2014). An investigation of the false discovery rate and the misinterpretation of p-values. Royal Society Open Science, London, U.K. 4. >López de Prado, M. (2019). A Data Science Solution to the Multiple-Testing Crisis in Financial Research. Journal of Financial Data Science, 1(1), 99-110. |
|
| 7. Textual Analysis and Large Language Models | 10 - 15 |
|
■ Evidence and probabilities ■ Broad issues involved in mining text ■ Text representation ■ Additional text representation approaches beyond “bag of words.” ■ Classification ■ Math behind Naïve Bayes classifiers ■ Training the Naïve Bayes classifiers ■ Optimizing for sentiment analysis ■ Evaluation of sentiment analysis results Readings for Data Mining & Machine Learning: Naïve Bayes & Text Mining 1. Provost, F. and T. Fawcett. (2013). Data Science for Business. Sebastopol, CA: O’Reilly Media Inc. • Chapter 9 – Evidence and Probabilities • Chapter10 – Representing and Mining Text 2. Jurafsky, D. and J. Martin. (2018). In Speech and Language Processing • Chapter 4 – Naïve Bayes and Sentiment Classification |
|
| 8. Ethical & Privacy, and Regulation | 8 - 12 |
|
■ Big data for business ■ Ethical issues ■ The ethics test ■ The nature of and business risks of artificial intelligence (AI) ■ Values that form the cornerstone of an ethical framework for artificial intelligence in business ■ The role of business decision-makers ■ General Data Protection Regulation (GDPR) ■ Separating ethics and compliance ■ Separating ethics and compliance ■ The GDPR Embedding Wheel ■ Doing good data science ■ Oaths and checklists ■ The five C’s ■ Taking responsibility for our creations (Data’s Day of Reckoning) Readings for Big Data & Machine Learning: Ethical & Privacy Issues 1. Institute of Business Ethics. (2016, June). Business Ethics and Big Data (IBE Issue 52). London, U.K. 2. Institute of Business Ethics. (2018, January). Business Ethics and Artificial Intelligence (IBE, Issue 58). London, U.K. 3. Institute of Business Ethics. (2018, May). Beyond Law: Ethical Culture and GDPR (IBE, Issue 62). London, U.K. 4. Loukides, M., M., H. Mason and DJ. Patil. Ethics and Data Science |
|
| 9. Fintech Applications | 15 - 25 |
|
■ Artificial intelligence and its techniques ■ Applications of AI and Five Technologies Trends that Leap-Frog AI ■ Machine learning and finance ■ Artificial Intelligence in Investment Management ■ Four Pillars for Transformation of Investment Management Firms ■ Adoption and Implementation Risks ■ Regulatory and supervisory issues around FinTech ■ Relationship between artificial intelligence, machine learning, and big data, and algorithms ■ Categories of machine learning algorithms ■ Drivers of the growth in the use of fintech and adoption of artificial intelligence ■ Use cases of artificial intelligence and machine learning in the financial sector ■ The micro-financial analysis of artificial intelligence and machine learning uses ■ The macro-financial analysis of uses of artificial intelligence and machine learning uses ■ Define the terms listed in the glossary ■ Alternative data and institutional investors ■ Applications of random forest regression algorithm to factor models ■ The applications of machine learning algorithms to stock selection ■ Applications of machine learning algorithms to empirical asset pricing ■ The most common errors made when machine learning techniques are applied to financial data sets ■ Using statistical techniques to evaluate trading strategies in the presence of multiple tests ■ Text mining and its applications in the insurance industry Readings for Big Data & Machine Learning in the Financial Industry 1. Deloitte. (2018) Artificial intelligence. 2. AQR Portfolio Group Solutions (2019). Can machines “learn” finance? 3. Deloitte. (2019) Artificial intelligence: The next frontier for investment management firms. 4. Financial Stability Board. (2017). Artificial Intelligence and Machine Learning in Financial Services: Market Developments and Financial Stability Implications. 5. Monk, A., M. Prins, and D. Rook. (2019). Rethinking Alternative Data in Institutional Investment. Journal of Financial Data Science, 1(1), 14-31. 6. Simonian, J., C. Wu, D. Itano and V. Narayanan. (2019). A Machine Learning Approach to Risk Factors: A Case Study Using the Fama–French–Carhart Model. Journal of Financial Data Science, 1(1), 32-44. 7. Rasekhschaffe, K. and R. Jones. (2019). Machine Learning for Stock Selection. Financial Analyst Journal, 13 June 2019 Volume 75, Issue 3. 8. Gu, S., B. Kelly, and D. Xiu. (2018). Empirical Asset Pricing via Machine Learning. 9. López de Prado, M. (2018). The 10 Reasons Most Machine Learning Funds Fail. The Journal of Portfolio Management, 44 (6) 120-133. 10. Harvey, C. R. and Y. Liu. (2014). Evaluating Trading Strategies. [Special 40th Anniversary Issue]. The Journal of Portfolio Management, 40(5), 108-118. 11. Zappa, D., M. Borrelli, G.P. Clemente, N. Savelli. Text Mining In Insurance. |
|
1.시험 장소 및 일정
FDP 시험일정
| Window | Registration Opens | Late Registration Begins | Registration Closes | |
|---|---|---|---|---|
| 2025 April | 2025.04.14-04.25(at Test Center) 2025.04.26-05.04(Remote) |
2024.12.16 | 2025.03.10 | 2025.03.31 |
| 2025 Nov | 2025.11.03-11.14(at Test Center) 2025.11.15-11.23(Remote) |
2025.01.02 | 2025.09.29 | 2025.10.20 |
시험장소는 Prometric Center 입니다.
| 장소 | 주말 실시 | 평일 실시 | 지도 |
|---|---|---|---|
| 서울시 중구 퇴계로 성우 빌딩 6층 HSF Inc. (HSF Inc., 6th floor, Seongwoo Building, Toegye-ro, Jung-gu, Seoul) |
o | o |
|
* 시험 응시 장소는 2가지 선택지가 있습니다.
• Option 1
- Prometric Testing Center에 직접 가서 시험을 치루는 것(대표 시험장소: 서울시 용산구 한남대로 20길 47-6 (2층/3층)).
- 시험기간 중 하루를 선택하고 Prometric Testing Center 사이트로 가서 예약하면 됩니다.
• Option 2
- Remotely Proctored Testing으로 수험생이 직접 장소를 선택하고, FDP에서 요구하는 카메라 환경 등을 구비하여 시험을 치루는 것.
- 시험기간 중 하루를 선택하고 원격 감독 시험을 요청하시면 됩니다.
2.시험 결제 및 취소 정책
1) FDP 재시험 시 Retake 비용 $500만 지불하고 시험 응시 가능합니다.
2) CAIA 멤버는 FDP 첫 시험 등록 시 시험비가 20% 할인됩니다.(CAIA ID number 제출)
1.시험 유의사항
• 시험 응시 준비물
여권외에 추가 신분증 혹은 본인명의의 신용카드, 체크카드 (여권과 동일한 영문명이 적혀있어야함)가 필요합니다.
총 2개의 신분증으로 이중체크 하오니 여권 외 신용카드, 추가 신분증 등을 지참하셔야 합니다.
• 체크아웃
시험을 완전히 종료할 시에 손을 들어 시험 진행요원에게 알리고 노트와 마커를 제출해야 하며, 시험이 끝남을 알린 다음에 시험장을 나갈 수 있습니다.
시험장을 나온 직후 시험 시간 중에 착석한 자리를 입증하는 증서를 받게 됩니다.
증서에는 시험 결과 발표 일정 등의 정보가 있습니다.
• 시험 진행 중 문제 사항 보고
수험생이 시험 센터 혹은 시험 진행요원이 시험 진행 중 행정 절차 관련 건의사항이 있는 경우, FDP 협회 이메일(candidate@fdpinstitute.org)로 연락하면 됩니다.
연락 시 해당 사건의 상세한 묘사(일자, 시험 센터명, 사건 유형, 관련자 이름, 보고자 연락처)를 반드시 포함하여야 합니다.
이메일 회신은 수신 이후 2~3주 정도가 소요될 수 있으며, 결과에 따라서 필요시 조치를 취할 것입니다.
2.채점 및 결과 발표
• 시험 채점
FDP 협회는 해당 시험 기간에 응시한 모든 수험생 답안이 회수된 이후 채점을 시작합니다.
이는 해당 시험 기간 중 모든 시험이 종료되기 전에는 채점할 수 없다는 의미입니다.
시험 출제 위원은 시험 시행 전후로 모든 문항을 검토하고, 오류를 찾습니다.
만약 출제 위원이 판단하기에 충분히 불명확한 사항을 포함하고 있는 문항은 시험 채점에서 제외될 수 있습니다.
• 시험 결과 및 결과 리포트
시험 결과는 마지막 시험 응시일자 이후 5주일 이내에 공개됩니다.
시험 결과를 받을 연락처를 변경하는 경우, 변경사항을 업데이트 해야 시험 결과를 적시에 받을 수 있습니다.
수험생의 시험 결과에 관한 정보는 철저히 기밀입니다. 시험 결과는 합격 혹은 불합격으로 확인이 가능합니다.
점수에 대한 자세한 사항은 명시 되지 않습니다.
• 점수 재검토 요청
시험 점수에 대해 의문을 가지는 수험생을 결과 리포트를 수령한 이후 점수 재검토 요청을 할 수 있습니다.
개별 토픽에서 획득한 점수는 절차에 따라 다시금 확인되고 보고된 점수와 비교될 것입니다.
이는 모든 문제가 다시 채점됨을 의미하지 않습니다. 점수 재검토 요청 비용은 $100입니다.
점수 재검토 요청은 FDP 협회 이메일(candidate@fdpinstitute.org)로 합니다.
결과 리포트를 수령한 후 30일 이내에 제출해야 합니다.
3. 시험 합격 후 유의사항
FDP 시험에 합격한 이후에는 아래의 두 과정을 수행하셔야 차터발급이 완료됩니다.
1. 윤리서약서 제출(complete and sign the Code of Ethics)
2. 두명의 추천인에게 추천서를 받은 후 제출(submit two professional references)
여기서 추천인은 반드시 FDP 차터홀더일 필요는 없고, 본인의 경력사항에 대해 증빙이 가능한 두명의 추천인에게 추천서를 받으시면 됩니다.