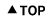|
요즘 에디터가 좀 이상해지면서 copy paste가 안되는 관계로....
1) Sa 에서 X_i 들은 A 집단에 포함되어있는 애들이라고 보시면 되고 X바는 A집단의 평균입니다. (빙고~^^)
2) 당연히 모집단의 sigma는 sample A의 Sa와는 다릅니다. 하지만 Sa는 sigma의 unbiased estimator이고 다를 것이라는 것을 알지만 가장 비슷한 추정치라고 생각되어서 (다른 alternative가 없습니다.) 그것을 사용하는 것입니다.
그리고 실제적으로 샘플링을 많이 (A~Z)까지 하지 않습니다.
샘플링은 1번 하고 거기서 X-bar와 S를 계산해서 그것으로 점추정, 구간추정을 합니다.
구간추정을 하기 위해서 X_bar의 분포가 필요하고 그래서 샘플링을 무한히 많이 한다는 가정을 하는 것 뿐입니다. (이론의 세계입니다.)
n은 샘플하나를 뽑을 때 그 샘플에 들어가는 X들의 갯수 입니다.
그래서 마지막 질문 (S들을 다 구해서 산술평균을 하는 것이 아닙니다.) 은 관련이 없습니다.
제가 설명드릴때 세계를 3개로 구분하면서 말씀드린것을 다시 곰곰이 생각해보셨으면 합니다.
(형이상학적인 모집단의 세계)
(샘플하나를 취해서 모집단을 추정하는 현실의 세계)
(샘플링을 무한히 많이 해서 X_bar의 분포를 구하는 이론의 세계)
두번째와 세번째 세계가 많이 섞여져서 질문을 하셨고.. 그래서 마구 헷갈리고 계신것 같아요.
다시 함번 질문을 읽어가면서 정리를 좀 하셔야할것 같습니다.
홧팅입니다.~~
|