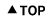|
population standard deviation은 5.97%(모수)이고, sample standard deviation(추정량의 기대값)이 6.67%
: 일반적으로 population standard deviation은 모르는 경우가 대부분 입니다.
그래서 우리는 sample을 뽑아서 population에 대해서 연구하게 됩니다.
sample이 population을 닮았을꺼라는 가정을 기본으로 하는거죠.
그러나 sample은 sampling할때마다 다른 추정치를 줍니다.
그런데 왜 unbiased라고 하느냐?
E(s) = sigma이기 때문입니다. 그러니까 우리가 sampling을 할 때마다 s를 계산하고..이 sampling을 무한히 한다고 가정하면
그것의 평균이 sigma와 같다는 것입니다. - 이것이 불편 추정량의 특성입니다.
sample standard deviation과 standard error of the sample mean의 차이점
: sample standard deviation은 sample하나를 뽑았을때 그 sample의 표준편차입니다.
---> standard error of the sample standard deviation은 sampling을 했을 때마다 sample의 표준편차를 계산하면 (s_1, s_2, s_3....) 이것의 표준편차입니다.
---> standard error of the sample mean은 sampling을 했을 때마다 sample의 평균를 계산하면 (x-bar_1, x-bar_2, x-bar_3, ...) 이것의 표준편차입니다.
마지막으로 sampling error라는 것이 있는데 이건 추정하고자 하는 parameter와 추정치의 차이입니다.
(parameter를 모르는 경우가 대부분이니까 알기 어렵겠죠?)
예를 들어 sampling error of the mean = x-bar - mu
sampling error of the standard deviation = s - sigma 입니다.
헷갈리시죠?
sampling error와 standard error 를 잘 구별하셔요~
|